
Blog #14 - Xây dựng hệ thống tìm kiếm nhạc bằng âm thanh với Python và Approximate Nearest Neighbors
Tình huống khó xử
Xin chào tất cả các bạn. Không biết đã bao giờ các bạn gặp phải một số tình huống dở khóc dở cười như thế này chưa:
Vào một ngày đẹp trời đang đi trên đường nghe thấy một bài nhạc Hàn hay lắm cơ mà chả biết tên nó là cái gì để mà search trên mạng. Mà khổ nỗi mình cũng chả biết tiếng Hàn nên cũng chả biết tìm kiếm thế nào cho nó ra
. Thế là cuối cùng đành phải ngậm đắng nuốt cay vì tội ngu ngoại ngữ.

Một hôm một người mà bạn lớ thương thầm nhớ trộm nhờ bạn tìm hộ một bài hát, bạn hăm hở tưởng chuyên nó sâu easy vì bạn là dân công nghệ nên nhận lời liền. Em cứ đưa lời đây, cả thế giới để anh lo. Ai ngờ em ấy chốt đến phịch một cái vào khuôn mặt đang hớn hở của bạn là Cái bài mà tèn ten ten tèn tén ten tèn ý anh. What the hell??? - em ấy gửi cho một đoạn nhạc không lời. Và chắc chắn khuôn mặt của bạn sẽ lại đáng thương như ngày nào.
Đến lúc đó bạn mới tự đặt ra cho mình một câu hỏi. Kể ra mà cái hệ thống nào chỉ cần đưa cho nó nghe bài hát mình đang nghe, nó sẽ tự tìm cho mình đó là bài hát nào thì hay biết mấy. Nếu bạn đã từng bị rơi phải tình cảnh như trên thì bài viết này chính là dành cho bạn. Hãy trở thành một dân công nghệ chân chính bằng cách tự build một hệ thống tìm kiếm bài hát bằng âm thanh cho riêng mình. OK chúng ta bắt đầu thôi nào.
Hiểu về dữ liệu âm thanh
Nếu không có không khí thì làm sao chúng ta có sự sống. Cũng như vậy chúng ta làm sao giải quyết được vấn đề nếu như không định nghĩa được vấn đề nó là cái gì phải không các bạn. Giống như việc tìm hiểu để cưa cẩm một cô gái, trước khi bước vào bài toán nào đó chúng ta cũng cần phải hiểu được bản chất của vấn đề, không thì tập xác định là sẽ thất bại dài dài. Hai tình huống bên trên chúng ta đang làm việc với dữ liệu dạng âm thanh. Vậy nên việc đầu tiên cần hiểu về dữ liệu dạng âm thanh trước đã nhé.

Một cách trực tiếp hay gián tiếp nào đó chúng ta vẫn tương tác với các dạng âm thanh hàng ngày. Đơn giản như tiếng lạch cạch khi thằng bên cạnh gõ bàn phím cũng làm bạn khó chịu, tiếng chị QA báo bugs làm cho bạn sợ hãi hay tiếng của crush vừa mới xuất hiện trong đầu đã làm bạn sướng đến mức phát điên cả ngày hôm đó. Tất cả những thứ đó được coi là dữ liệu dạng âm thanh. Tuy nhiên ở góc độ của máy tính chúng ta có thể hiểu dữ liệu dạng âm thanh là một chuỗi các biên độ kèm thời gian tương ứng tức là dữ liệu dạng âm thanh có dạng sóng.
Trên thực tế dữ liệu mà chúng ta thu được từ âm thanh là một dữ liệu phi cấu trúc, có nghĩa là chúng ta không thể biết được cấu trúc rõ ràng của nó. Chính vì thế nếu bạn bị người yêu mắng mà bạn cũng muốn chiếc máy tính của bạn hiểu được understandable thì cần phải chuyển đổi tiếng đó thành dạng biên độ tương ứng với âm thanh như trên. Tuy nhiên một câu chuyện xảy ra là chúng ta không thể nào lưu hết được tần số theo trục thời gian (vì nó là vô hạn). Thay vào đó người ta nghĩ ra việc xấp xỉ hoá chúng, tức là khoảng 0.005s thì lưu lại giọng của cô người yêu bạn một lần. Do đặc tính của tai người (nghe người yêu mắng nhiều thành quen) bạn cũng sẽ không nhận ra được các âm thanh đó là rời rạc. Người ta gọi đó là kĩ thuật lấy mẫu âm thanh - sampling of audio data và việc bạn lấy bao nhiêu mẫu trong một giây - có thể là 40000 hoặc 16000 chẳng hạn được gọi là sampling rate.
Chúng ta có thể hình dung nó như sau, trong đó các biên độ amplitude được thể hiện dưới hình sóng uốn lượn.

Tương ứng với mỗi điểm thời gian $t_i$ chúng ta sẽ có một biên độ $a_i$ và cứ như thế, âm thanh được tạo ra nhờ sự thay đổi các biên độ theo thời gian.
Có một các khác để biểu diễn dữ liệu dạng âm thanh này đó chính là biểu diễn nó theo miền tần số. Hãy tưởng tượng rằng chúng ta chia giọng nói đanh thép của cô người yêu thành các phổ tần số khác nhau tương ứng theo thời gian, đồng nghĩa với việc chúng ta cần nhiều điểm để biểu diễn dữ liệu tại một thời điểm nhất định. Tất nhiên là tốc độ lấy mẫu sampling rate phải càng cao càng tốt. Chúng ta có thể tham khảo hình vẽ sau:

Ở đây, chúng ta sẽ tách một tín hiệu âm thanh thành 3 tín hiệu thuần khác nhau, giờ đây có thể được biểu diễn dưới dạng 3 giá trị duy nhất trong miền tần số.
Các phương pháp trích chọn đặc trưng
Đặc trưng là gì? Hiểu đơn giản đó là cái gì đó để phân biệt các đối tượng ví dụ như đặc trưng của mình là đẹp trai, vui tính, thân thiện, thích bóng đá, yêu văn nghệ chẳng hạn. Tương tựu như vậy đặc trưng của âm thanh chính là các tham số dùng để để phân biệt, nhận dạng, so khớp các mẫu âm thanh với nhau. Chúng ta có thể bắt gặp cụm từ Features Extraction ở rất nhiều nơi đặc biệt là các bài viết về Học máy hay Deep Learning. Trong phần này chúng ta sẽ tìm hiểu về các cách trích chọn đặc trưng với một hệ thống âm thanh.
Có một đặc điểm là kích thước toàn bộ tín hiệu âm thanh rất lớn, tín hiệu âm thanh dễ bị biến đổi trong các điều kiện khác nhau nên không thể sử dụng toàn bộ dữ liệu âm thanh làm vector đặc trưng. Hai điều kiện tiên quyết của vector đặc trưng tín hiệu âm thanh là:
- Phải phân biệt được các mẫu âm thanh
- Phải tối thiểu hóa chiều dài vector đặc trưng bằng cách loại bỏ tối đa thông tin dư thừa
Về cơ bản chúng ta có hai cách tiếp cận để trích chọn đặc trưng của âm thanh đó là theo cách truyền thống và theo cách tiếp cận của Deep Learning.
Cách tiếp cận truyền thống
Trong cách tiếp cận truyền thống, các vector đặc trưng của tín hiệu âm thanh được xây dựng từ các đặc trưng vật lý của âm thanh như độ to, độ cao, năng lượng, phổ tần số,… Gần đây, một số nghiên cứu trên thế giới tập trung vào một cách tiếp cận khác, trong đó áp dụng các kiến thức về xử lý tín hiệu âm thanh, về phân tích mô hình tạo âm thanh, mô hình cảm thụ âm thanh của con người có thể giúp việc tính toán vector đặc trưng âm thanh được chính xác và hạn chế tối đa thông tin dư thừa.
Cách tiếp cận bằng Deep Learning
Cách tiếp cận theo Deep Learning có thể thường được quy về các bài toán Xử lý ảnh. Ví dụ phổ tần số hoặc các đặc trưng của đoạn âm thanh được coi như một bức ảnh với 3 kênh màu. Lúc đó chúng ta có thể sử dụng các mạng CNN để trích chọn đặc trưng. Việc này đòi hỏi quá trình training trên cả tập dữ liệu để mô hình học được các tham số làm đặc trưng cho đoạn âm thanh. Về việc sử dụng mạng CNN thì các bạn có thể tham khảo trong một số bài viết khác của mình.
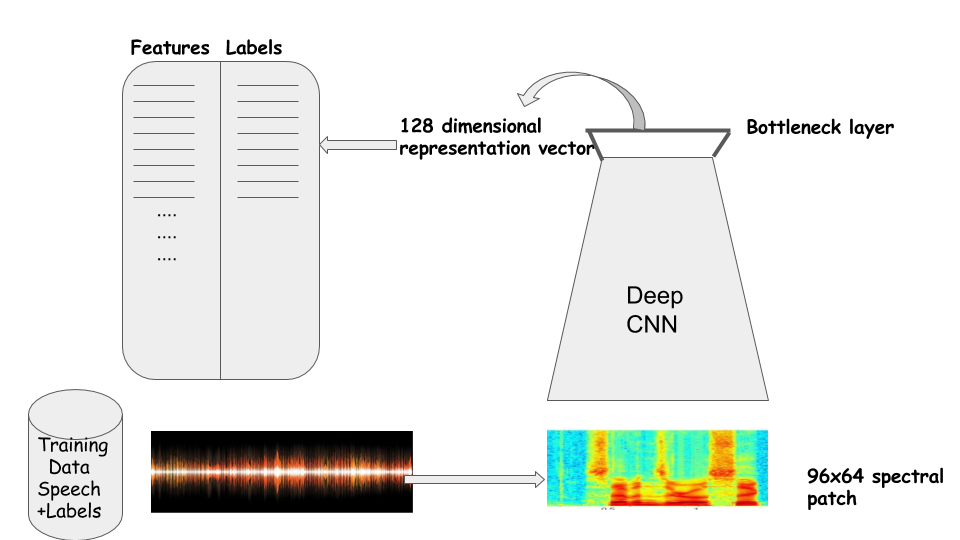
Các nghiên cứu trên thế giới về phương pháp trích chọn vector đặc trưng cho hệ thống tìm kiếm âm nhạc theo nội dung thường sử dụng các đặc trưng truyền thống trong xử lý âm thanh. Trong bài viết này mình sẽ tập trung vào các phương pháp truyền thống trước. Các phương pháp sử dụng mô hình Deep Learning sẽ được bàn tới ở một bài viết khác.
Xây dựng hệ thống tìm kiếm bài nhạc
Cấu trúc hệ thống
Về cơ bản một hệ thống tìm kiếm bài nhạc bao gồm các thành phần sau:

-
L1 - GUI: là giao diện phía người dùng, cho phép nhập vào audio cần tìm kiếm
-
L2 - Search Engine: áp dụng các giải thuật tìm kiếm của chúng ta
-
L3 - Database: là nơi lưu trữ các thông tin đặc trưng của các kho bài hát. Chúng ta sử dụng các thông tin này để so sánh.
Trong đó hệ thống của chúng ta sẽ xử lý qua 3 bước:
- S1 - biểu diễn đặc trưng âm thanh: chính là phần chúng ta đã bàn ở phần trước. Nôm na là lấy ra các thành phần đẹp trai, vui tính, thân thiện, thích bóng đá, yêu văn nghệ hay xinh xắn, có duyên, ngoan hiền, dễ bảo của âm thanh. Giúp chúng ta căn cứ vào đó để tìm kiếm, so sánh các đoạn âm thanh khác nhau.
- S3 - một phương pháp để đánh giá độ tương tự: nghe thì có vẻ nguy hiểm nhưng có thể hiểu đơn giản đó là cách chúng ta so sánh xem giữa hai đoạn âm thanh giống nhau cỡ nào. Ví dụ như một ông nào đó mà đẹp trai, vui tính, thích bóng đá, thích hát hò thì chắc là giống mình đến 99% rồi.
OK chúng ta sẽ đi xây dựng từng thành phần trong đó trước. Cụ thể đó chính là sáu thành phần trên nhé.
Xây dựng database bài nhạc
Việc đầu tiên của hệ thống đó là phải xây dựng được một database nhạc nhẽo. Đơn giản thôi các bạn chỉ cần lên zing download về là được. Ví dụ ở đây kho nhạc của mình có khoảng hơn 14 bài hát nhạc trẻ
Các bạn có thời gian thì có thể tạo thêm nhiều bài hát nữa. Mình chỉ làm demo nên sử dụng luôn mấy bài nhạc có sẵn trong máy cho nhanh ![]()
![]()
![]()
OK giờ đã có dữ liệu rồi, chúng ta tiến hành sang bước thứ hai đó là trích chọn đặc trưng của dữ liệu.
Trích chọn đặc trưng
Như đã nói ở trên chúng ta sẽ cần phải có bước trích chọn đặc trưng đối với từng đoạn âm thanh. Ở đây mình sử dụng thư viên librosa và thư viện python_speech_features để trích chọn đặc trưng. Các bạn có thể cài đặt nó bằng cách sau
pip install librosa
pip install python_speech_features
Sau đó chúng ta tiến hành import các thư viện cần thiết
import os
import glob
import librosa
from tqdm import tqdm
import numpy as np
from python_speech_features import mfcc, fbank, logfbank
Đặc trưng dựa trên biên độ âm thanh
Như đã nói ở trên chúng ta có thể biểu diễn thông tin âm thanh theo hai hình thức. Ở hình thức thử nhất chúng ta sẽ định nghĩa một tốc độ lấy mẫu và giá trị về biên độ âm thanh làm đặc trưng cho dữ liệu. Đại lượng này có thể được đọc ra bằng thư viên librosa theo câu lệnh sau:
song = 'path_to_audio'
y, sr = librosa.load(song, sr=16000)
trong đó y là giá trị của biên độ và sr là sampling rate - tốc dộ lấy mẫu. Tuy nhiên cũng như đã bàn ở trên thì việc lấy tham số này làm đặc trưng của âm thanh sẽ dẫn đến nhiều các sai số nhất là đối với bài toán Tìm kiếm âm thanh của chúng ta. Chính vì thế chúng ta sẽ cần phải có một đại lượng khác đó là MFCC - Mel Frequency Cepstral Coefficient đây là một trong những phương pháp lấy đặc trưng âm thanh dựa trên phổ tần số phổ biến trong các hệ thống nhận dạng giọng nói, tổng hợp tiếng nói …. Chúng ta sẽ cùng tìm hiểu cụ thể trong phần tiếp theo
Đặc trưng dựa trên đường bao phổ tần số MFCC
Tai của con người nhận biết được những âm thanh có tần số thấp (<1kHz) tốt hơn những âm thanh có tần số cao. Vì vậy điều quan trọng là cần làm nổi bật lên những âm thanh có tần số thấp hơn là tần số cao. Dải tần số của tín hiệu tiếng nói là khoảng 10kHz. Tần số tiếng nói là dưới 3kHz, cao hơn các thành phần tần số chính liên quan đến người nói, âm nhạc, dụng cụ âm thanh hoặc hiệu ứng. Formants cũng là thông tin quan trọng.
Cepstral là một phương pháp để trích chọn đặc trưng âm thanh. Trích chọn tham số đặc trưng âm thanh dựa trên hai cơ chế:
- Mô phỏng lại quá trình cảm nhận âm thanh của tai người.
- Mô phỏng lại quá trình tạo âm của cơ quan phát âm.
Về lý thuyết thì là như vậy. Chúng ta có thể sử dụng thư viện python_speech_features để xử lý MFCC mà không cần mất quá nhiều thời gian. Chúng ta định nghĩa hàm sau
def extract_features(y, sr=16000, nfilt=10, winsteps=0.02):
try:
feat = mfcc(y, sr, nfilt=nfilt, winstep=winsteps)
return feat
except:
raise Exception("Extraction feature error")
trong đô tham số nfilt tương ứng với việc độ dài của mỗi thuộc tính MFCC là 10 và winsteps tương ứng với việc chúng ta sẽ lấy mẫu theo 0.02 giây cho một thuộc tính MFCC. Như vậy mà nói thì 1 giây chúng ta sẽ sinh ra được 50 MFCC đặc trưng cho âm thanh. Tuy nhiên việc lấy 10 MFCC và thời gian lấy mẫu là 0.02 giây dường như là quá nhỏ và chưa đủ đặc trưng. Chính vì thế chúng ta sẽ gộp 10 MFCC này lại thành một vector 100 chiều. Đại diện cho mỗi đoạn âm thanh 200ms. Chúng ta định nghĩa hàm đó như sau:
def crop_feature(feat, i = 0, nb_step=10, maxlen=100):
crop_feat = np.array(feat[i : i + nb_step]).flatten()
print(crop_feat.shape)
crop_feat = np.pad(crop_feat, (0, maxlen - len(crop_feat)), mode='constant')
return crop_feat
Ví dụ chúng ta thử extract thuộc tính của bài hát Ai còn chờ ai ở vị trí giây thứ 1 đến 1.2s. Chúng ta làm như sau:
y, sr = librosa.load('./Ai-Con-Cho-Ai-Anh-Khang.mp3', sr=16000)
feat = extract_features(y, i=50)
print(crop_feature(feat).shape)
>>> (100, )
Chúng ta có thể coi các đoạn vector 100 chiều này là đặc trưng của mỗi đoạn âm thanh có độ dài 200ms. Việc cần làm của chúng ta là sinh ra đầy đủ các đặc trưng của các bài hát trong cơ sở dữ liệu .Để tránh mất mát thông tin chúng ta sẽ trượt trên trục thời gian của âm thanh 100ms. Chúng ta sẽ xử lý như sau:
for song in tqdm(os.listdir(data_dir)):
song = os.path.join(data_dir, song)
y, sr = librosa.load(song, sr=16000)
feat = extract_features(y)
for i in range(0, feat.shape[0] - 10, 5):
features.append(crop_feature(feat, i, nb_step=10))
songs.append(song)
Đến đây chúng ta đã tiến hành xong việc sinh ra các vector đặc trưng của các bài hát trong cơ sở dữ liệu. Bây giờ các bạn sẽ lưu lại các đặc trưng này cho chắc cú đề phòng mất điện lại phải sinh lại.
import pickle
pickle.dump(features, open('features.pk', 'wb'))
pickle.dump(songs, open('songs.pk', 'wb'))
OK giờ chúng ta sẽ sang phần tiếp theo. đó là việc tìm kiếm và truy vấn.
Truy vấn bằng Approximate Nearest Neighbors
Hãy tưởng tượng bạn phải truy vấn trên một lượng thông tin rất khổng lồ. Hàm trăm ngàn giờ âm thanh sẽ tương ứng với hàm tỷ vector đặc trưng là vector số thực 100 chiều. Nếu như tìm kiếm brute-force thì có mà đến Tết cũng chưa chắc đã tìm xong được một bài. Đây chính là lúc các bạn cần sử dụng đến giải thuật Approximate Nearest Neighbors để tìm kiếm trên không gian lớn với tốc độ nhanh.
Để tìm hiểu thêm về giải thuật này các bạn có thể tham khảo các bài viết khác trên Viblo. Ở đây chúng ta sẽ sử dụng một thư viên indexing được coi là tốt nhất trên việc tìm kiếm vector số thực hiện tại đó là annoy index. Các bạn có thể install nó bằng câu lệnh
pip install annoy
Việc tiếp theo đó là add dữ liệu vào trong annoy indexing
from annoy import AnnoyIndex
f = 100
t = AnnoyIndex(f)
for i in range(len(features)):
v = features[i]
t.add_item(i, v)
và tạo cây index
t.build(100) # 100 trees
t.save('music.ann')
Việc load lại cây indexing trong annoy cũng vô cùng đơn giản
u = AnnoyIndex(f)
u.load('music.ann')
Đến lúc này các bạn có thể tìm kiếm với một đoạn nhạc mà các bạn chưa biết nó là bài hát nào. Sau đó sử dụng kĩ thuật voting để tìm ra top các bài hát gần tương tự nhất với đoạn nhạc của bạn.
Tìm kiếm bài hát tương tự
Các bạn cũng cần phải thực hiện các thao tác extract đặc trưng với một đoạn nhạc của bạn giống như việc trích xuất đặc trưng từ trong database.
song = os.path.join(data_dir, 'audio.mp3')
y, sr = read_song_frequency(song)
feat = extract_features(y)
sau đó tiến hành tìm kiếm tương tự và lưu các kết quả vào một mảng. Ở đây mình lưu lại tất cả các kết quả có xuất hiện trong top 5 của truy vấn vào trong mảng results
results = []
for i in range(0, feat.shape[0], 10):
crop_feat = crop_feature(feat, i, nb_step=10)
result = u.get_nns_by_vector(crop_feat, n=5)
result_songs = [songs[k] for k in result]
results.append(result_songs)
results = np.array(results).flatten()
Và cuối cùng đó là đưa ra bài hát phù hợp nhất với đoạn âm thanh các bạn vừa nhập vào .
from collections import Counter
most_song = Counter(results)
most_song.most_common()
>>> [('./Anh-Dang-O-Dau-Day-Anh-Huong-Giang.mp3', 430),
('./Xe-Dap-Thuy-Chi-M4U.mp3', 72),
('./Anh-Mo-Anh-Khang.mp3', 36),
('./Buc-Thu-Tinh-Dau-Tien-Tan-Minh.mp3', 35),
('./Chieu-Nay-Khong-Co-Mua-Bay-Thai-Tuyet-Tram.mp3', 31),
('./Anh-Se-Tot-Ma-Pham-Hong-Phuoc-Thuy-Chi.mp3', 28),
('./Ai-Con-Cho-Ai-Anh-Khang.mp3', 22),
('./Sai-Nguoi-Sai-Thoi-Diem-Thanh-Hung.mp3', 22),
('./Suy-Nghi-Trong-Anh-Nam-Cuong-Khac-Viet.mp3', 19),
('./Cang-Niu-Giu-Cang-De-Mat-Mr-Siro.mp3', 19),
('./Thang-Dien-JustaTee-Phuong-Ly.mp3', 12),
('./Em-Khong-The-Tien-Tien-Touliver.mp3', 10),
('./Vo-Tinh-Xesi-Hoaprox.mp3', 9),
('./Mau-Nuoc-Mat-Nguyen-Tran-Trung-Quan.mp3', 5)]
Chúng ta có thể thấy được rằng đoạn nhạc mà mình thử nhập vào sẽ gần với bài hát Anh đang ở đâu đấy anh nhất. Và đó chính là ca khúc mà chúng ta cần tìm.
Xây dựng giao diện demo
Do đêm đã về khuya nên mình xin được khất phần này nhé. ![]()
![]()
![]()
Kết luận
- Sử dụng MFCC để trích chọn đặc trưng cho âm thanh đem đến hiệu quả khá tốt
- Sử dụng annoy indexing giúp cho việc truy vấn được nhanh hơn
- Nếu khi tichs hợp giao diện và một lượng data lớn thì đây là một ứng dụng rất hữu ích giúp các bạn tìm kiếm các bài hát, đoạn nhạc một cách nhanh chóng.
Để lại bình luận