
Blog #1 - Những bài toán cơ bản trong Machine Learning và ứng dụng
Khi ngồi viết Blog này tôi chợt nhớ lại những kỉ niệm ngày đầu tôi tìm hiểu về Machine Learning. Và bài toán đầu tiên tôi tìm hiểu đó chính là Hồi quy ứng dụng trong bài toán định gía nhà đất. Từ Hồi quy nghe nó có một sức hút đến kì lạ và làm cho tôi say mê tìm hiểu về Machine Learning từ đó.
Hồi quy, phân lớp, phân cụm, học có giám sát, học không có giám sát… là những từ khóa mà mỗi người học về Machine Learning bắt buộc phải tìm hiểu qua. Bài viết này tóm lưọc một cách cơ bản nhất các khái niệm đó cũng như tổng hợp những ứng dụng của Machine Learning áp dụng các phưong pháp này. Chúng ta cùng nhau tìm hiểu kĩ hơn về chúng nhé
Khái niệm học máy - Machine Learning
Có thể bạn đã nghe đến khái niệm này ở đâu đó nhưng tôi cũng xin được mạn phép trình bày lại ở đây. Chúng ta có thể hiểu khái niệm này như sau:
Học máy - Machine Learning là một lĩnh vực của trí tuệ nhân tạo liên quan đến việc nghiên cứu và xây dựng các kĩ thuật cho phép các hệ thống “học” tự động từ dữ liệu để giải quyết những vấn đề cụ thể. Theo Wikipedia
Tuy nhiên chúng ta có thể hiểu nôm na rằng
Học máy là ngành khoa học giúp máy tính dự đoán được các dữ liệu mới từ các dữ liệu đã biết thông qua các giải thuật học máy
Và hiện nay với lượng dữ liệu khổng lồ của người dùng Internet cùng với sự bùng nổ của cách mạng phần cứng càng làm cho tốc độ máy tính được cải thiện thì Học máy đang trở thành xu hướng và ngày càng len lỏi sâu vào cuộc sống của chúng ta. Có lẽ sau kỉ nguyên của Internet of Things - IoT sẽ là kỉ nguyên của Artificial Inteligence of Things - AIoT và người ta cũng ví Trí tuệ nhân tạo nói chung cũng như Học máy nói riêng giống như một Cuộc cách mạng công nghiệp lần thứ 4.
Một số vấn đề cơ bản trong Machine Learning
Thực sự mà nói thì đến bây giờ tôi cũng chưa thể tìm hiểu hết được những vấn đề của Machine Learning chính vì thế nên chúng ta mới gặp nhau ở Blog này để giao lưu học hỏi và bổ sung kiến thức cho nhau. Có thể nói phạm vi ứng dụng của Machine Learning là rất rộng và xuất hiện ở rất nhiều ngành nghề, lĩnh vực khác nhau. Có thể kể đến như hệ thống nhận dạng hình ảnh, robot thông minh, chatbot, xử lý tiếng nói…. Chúng ta có thể xem thêm một số ứng dụng nổi bật của Machine Learning trong video sau
Mặc dù có rất nhiều ứng dụng trên các mảng khác nhau, tuy nhiên chúng ta có thể quy về một vài bài toán phổ biến trong Machine Learning như sau:
Phân loại nhị phân - Binary Classification
Là một trong những bài toán phân loại phổ biến nhất trong Machine Learning, như cái tên của nó cũng cho thấy ý nghĩa của bài toán này rồi phải không các bạn. Nhị phân có nghĩa là bài toán xem xét đến hai đối tượng. Về mặt toán học, chúng ta xem xét một vector dữ liệu trong tập dữ liệu được gán nhãn với class với nhận 2 giá trị 0 hoặc 1 tức là chỉ có 2 trạng thái, 2 class chẳng hạn như bài toán phân loại hoa quả. Giả sử chúng ta có hia loại quả trong rổ là cam và táo chúng ta cần tìm một cách nào đó để tách riêng hai loại quả này ra làm hai phần riêng biệt sao cho càng chính xác càng tốt.
 Rõ ràng rằng việc phân loại này đã có từ rất lâu, lâu lắm rồi cơ. Tôi nhớ rằng hình như trong câu truyện cổ tích Tấm Cám hồi xưa đã có vụ mụ dì ghẻ trộn thóc với gạo rồi bắt cô Tấm nhặt hết số thóc và gạo riêng làm hai đống mới được đi chơi mà. Không biết hồi đó ông Bụt có dùng Machine Learning hay không nhưng ở thời điểm hiện tại thì Machine Learning có thể giúp chúng ta phân loại thóc và gạo chuẩn như Bụt rồi. Tất nhiên là trong thời hiện đại này chẳng ai rảnh rỗi để đi làm cái việc trộn thóc với gạo lại để rồi mất công ngồi nhặt riêng từng đống thế kia tuy nhiên cũng có một số bài toán tương tự được áp dụng Phân lớp nhị phân và tiêu biểu nhất đó là Email Spam Filtering được áp dụng vô cùng phổ biến hiện nay.
Rõ ràng rằng việc phân loại này đã có từ rất lâu, lâu lắm rồi cơ. Tôi nhớ rằng hình như trong câu truyện cổ tích Tấm Cám hồi xưa đã có vụ mụ dì ghẻ trộn thóc với gạo rồi bắt cô Tấm nhặt hết số thóc và gạo riêng làm hai đống mới được đi chơi mà. Không biết hồi đó ông Bụt có dùng Machine Learning hay không nhưng ở thời điểm hiện tại thì Machine Learning có thể giúp chúng ta phân loại thóc và gạo chuẩn như Bụt rồi. Tất nhiên là trong thời hiện đại này chẳng ai rảnh rỗi để đi làm cái việc trộn thóc với gạo lại để rồi mất công ngồi nhặt riêng từng đống thế kia tuy nhiên cũng có một số bài toán tương tự được áp dụng Phân lớp nhị phân và tiêu biểu nhất đó là Email Spam Filtering được áp dụng vô cùng phổ biến hiện nay.
Phân loại đa lớp - Multiclass Classification
Tương tự với logic của phân loại nhị phân được mô tả ở phần trên, tuy nhiên có một điểm khác biết đó là số tượng class trong trường hợp này không còn là 2 nữa mà là một số nhiều hơn 2 tức là . Một ví dụ bài toán này đó chính là việc phân loại ngôn ngữ của các bài post trong một blog và các class ở đây chính là các ngôn ngữ được phân loại như (English, French, German, Spanish, Hindi, Japanese, Chinese, . . . ). Điểm khác biệt lớn nhất có thể thấy đó chính là độ chính xác hay chính là cost error của bài toán. Rõ ràng rằng việc phân biệt 2 sự vật và hiện tượng dễ hơn rất nhiều so với nhiều sự vật hiện tượng. Cũng giống như khi chúng ta gặp nhiều người thì chuyện quên mật vài người cũng là chuyện bình thường thôi. Bài toán phân loại đa lớp được áp dụng phổ biến trong một số vấn đề thực tế như nhận dạng khuôn mặt, nhận dạng chữ viết tay, nhận dạng ô tô…. Mọi người có thể tham khảo một số tập dữ liệu nổi tiếng như ImageNet, CIFAR-10… đã được áp dụng trong vấn đề này.

Hồi quy - Regression
Chúng ta đã tìm hiểu qua hai lại bài toán phân lớp, đặc điểm của các bài toán này đó chính là target variable là 2 hoặc nhiều giá trị rời rạc. Thực tế có những trường hợp không mang giá trị rời rạc mà mang giá trị liên tục Ví dụ như sự biến động về giá cổ phiếu, điểm của một sinh viên, giá bán của một ngôi nhà. Về bản chất, phân tích hồi quy chính sẽ ước lượng mối quan hệ giữa các tham số (variables) trong mô hình mà chúng ta đang xét. Quay về trên quan điểm của xác suất thống kê, tôi vẫn nhớ quan điểm của một người thầy rằng “Không có một sự kiện nào trên đời là ngẫu nhiên, những thứ đang cho là ngẫu nhiên chỉ là những sự kiện ta chưa tìm ra được mô hình để biểu diễn quy luật của chúng”.
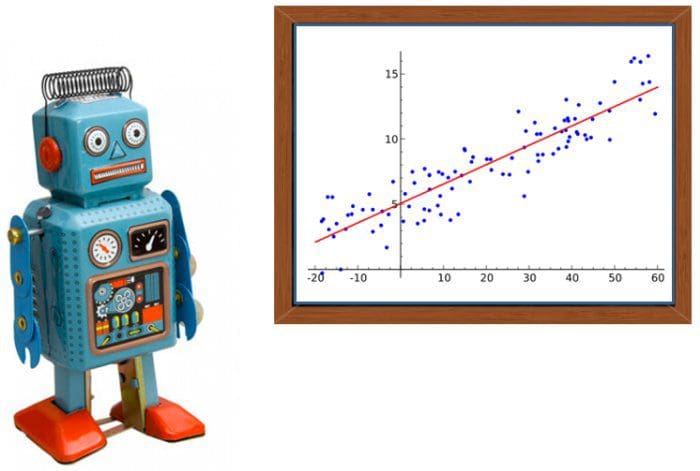
Chúng ta giả sử như phát biểu của ông thầy kia là đúng và tưởng tượng chúng ta đang là những người đánh xổ số. Giả sử rằng chúng ta có thể tìm ra được mối liên hệ giữa kết quả xổ số của một ngày với một vài tham số dễ thương như sau:
- Biến biểu diễn số trẻ em sinh ra trong ngày hôm nay
- Biến biểu diễn số người chết đi trong ngày hôm nay
- Biến biểu diễn lượng mưa trong ngày hôm nay
- Biến biểu diễn số thằng bị thất tình trong ngày hôm nay
- …
Và giả sử rằng kết quả xổ số của ngày hôm nay phụ thuộc một cách nào đó vào số người mới sinh, số người chết, lượng mưa và số thằng thất tình… Tức là chúng ta có thể viết dưới dạng toán học như sau:
Kết quả xổ số:
Hàm của chúng ta là gì??? Đó là công việc của giải thuật hồi quy, việc của chúng ta đó là hãy sưu tập cho máy tính một tập dữ liệu gốc thật chuẩn (training dataset). Sau khi tìm ra được các tham số phụ thuộc ví dụ như:
chúng ta sẽ sử dụng để so sánh nó trên tập dữ liệu kiểm tra (testing dataset). Thay đổi các phương pháp hồi quy cho đến khi sai số trên tập dữ liệu kiểm tra là nhỏ nhất. Như vậy chúng ta đã có một mô hình hồi quy sử dụng để tính toán kết quả xổ sổ rồi. Việc còn lại là dựa vào các giá trị cho , , …. áp vào mô hình rồi lấy kết quả đi đánh xổ số và tự tin với xác suất thắng lợi giống y như xác suất cao nhất bạn đạt trên tập dữ liệu kiểm tra. Qúa thú vị phải không nào. Hi vọng qua ví dụ hơi hoang tưởng trên bạn có thể hình dung ra được việc sử dụng phương pháp hồi quy trong bài toán dự đoán là như thế nào. Tất nhiên, trên thực tế người ta đã sử dụng mô hình hồi quy để ứng dụng vào các bài toán như:
- Dự đoán giá cả của sản phẩm
- Dự đoán biến động chứng khoán
- Dự đoán thời tiết
- …
Phân cụm - Clustering
 Các ví dụ được thảo luận ở phần trên thường phải sử dụng một tập dữ liệu đã được phân lớp hoặc đã biết trước giá trị của target variable nhưng thực tế thì không phải trường hợp nào chúng ta cũng có thể thu thập được một tập dữ liệu hoàn thiện như vậy. Chính vì lẽ đó nên chúng ta mới phát sinh ra một nhu cầu mới đó chính là Học từ những dữ liệu tự do tức là các dữ liệu chưa được gán nhãn trước đó. Các giải thuật dạng này được gọi là Học không có giám sát - Unsupervised Learning và tiêu biểu cho chúng là giải thuật phân cụm - Clustering:. Có một ví dụ cho dễ hình dung việc phân cụm này giống như việc có ai đó chúng ta đưa ra một đống tiền trước mặt và ra một câu đố Hãy phân loại đống tiền này thành hai loại. Ở đây số cụm của chúng ta và áp dụng những tiêu chí gì để phân cụm thì là tùy vào cách suy nghĩ của mỗi người, miễn là mỗi đống tiền nhỏ có chung một đặc điểm nào đó. Ví dụ như chúng ta có thể phân theo các cách sau:
Các ví dụ được thảo luận ở phần trên thường phải sử dụng một tập dữ liệu đã được phân lớp hoặc đã biết trước giá trị của target variable nhưng thực tế thì không phải trường hợp nào chúng ta cũng có thể thu thập được một tập dữ liệu hoàn thiện như vậy. Chính vì lẽ đó nên chúng ta mới phát sinh ra một nhu cầu mới đó chính là Học từ những dữ liệu tự do tức là các dữ liệu chưa được gán nhãn trước đó. Các giải thuật dạng này được gọi là Học không có giám sát - Unsupervised Learning và tiêu biểu cho chúng là giải thuật phân cụm - Clustering:. Có một ví dụ cho dễ hình dung việc phân cụm này giống như việc có ai đó chúng ta đưa ra một đống tiền trước mặt và ra một câu đố Hãy phân loại đống tiền này thành hai loại. Ở đây số cụm của chúng ta và áp dụng những tiêu chí gì để phân cụm thì là tùy vào cách suy nghĩ của mỗi người, miễn là mỗi đống tiền nhỏ có chung một đặc điểm nào đó. Ví dụ như chúng ta có thể phân theo các cách sau:
- Tiền giấy một đống, tiền polime một đống
- Tiền chẵn một đống, tiền lẻ một đống
- Tiền mới một đống, tiền cũ một đống
- …
Rõ ràng mỗi người có một cách lựa chọn khác nhau với cùng một số tương ứng với từng thuật toán phân cụm sẽ cho các kết quả khác nhau. Ngoài ra việc phân cụm còn phụ thuộc rất nhiều vào số cụm nữa. Tôi sẽ có một bài viết riêng của Blog này để viết về các thuật toán Clustering tuy nhiên trong thời điểm này các bạn chỉ cần hiểu tư tưởng của nó là đủ. Chúng ta có thể thấy một vài trường hợp áp dụng của Crustering như sau:
- Clustering: có thể được áp dụng trong các bước tiền xử lý dữ liệu với các bài toán supervised learning nhưng dữ liệu chưa được gắn nhãn đầy đủ hoặc bị gán nhãn sai.
- Phân chia dữ liệu thành các Clurster giúp làm nổi bật cấu trúc đặc trưng của dữ liệu. Áp dụng trong các bài toán xử lý hệ genes hoặc cấu trúc protein.
- …
Tổng kết
Machine Learning là một lĩnh vực rất thú vị. Tuy nhiên để tìm hiểu sâu về nó chúng ta đòi hỏi phải bỏ ra thời gian và công sức. Bản thân tôi bị lôi cuốn bởi những dòng dữ liệu và tôi cảm thấy đam mê với những giải thuật nhằm tìm ra được điều kì diệu từ những đống dữ liệu đó. Hãy cùng theo dõi những bài viết tiếp theo của tôi để cùng nhau chia sẻ những điều hay, những điều mới mẻ, những kiến thức về Machine Learning nhé. Một lần nữa cảm ơn các bạn đã theo dõi blog của tôi.
Thân ái Phạm Văn Toàn
Để lại bình luận